工程治理
收录于 工程治理体系
我们组拿了第一个黑旗以后,我开始让客户问题反推技术债
后来我慢慢想明白,团队自己觉得难受的地方,未必就是客户最痛的地方。对内部治理来说,先别急着重搭系统,先用企业微信和 CLI 把问题接住、把 SOP 和 checklist 管起来,很多事其实已经够用了。
我接手组里的质量工作时,最刺痛我的,其实是我们组第一次拿了黑旗——一次明确的质量告警。那一刻我才意识到,问题出在整个响应机制已经失控了:一线在群里到处找人,谁先看到谁先回,谁先回谁先背锅。表面上每个问题都有人接,实际上整个系统都在靠人肉硬拖。
撑不住了。
那段时间我脑子里一直有个问题甩不掉。我们内部也会天天讨论哪个模块烂、哪个地方该重构、哪块历史债看着最难受,可这些真的是现在最该优先解决的问题吗?后来我慢慢想明白了,质量治理最容易做偏的地方,就是团队总会先修自己看着不舒服的问题。可系统眼下最痛的,很多时候恰恰在外部——反复被追问、反复影响交付的那批问题上,内部觉得最差的地方倒未必排在前面。
也就是从那时起,我开始把这件事往另一个方向拧:别再先按团队自己的感受排优先级。先看客户和一线反复感知到什么问题,再用这些问题去定义技术债、资产积累和后续门禁。
当时我也没想那么远。先卡住我的,其实是群里这种接问题的方式已经撑不住了。谁看见谁回,谁回了谁就往下扛,这个状态不先改,后面讲什么治理都没用。
所以我最早做的事其实很小,就是先找现成入口把问题接进来。企业微信本来就是大家每天都在用的地方,开发平时也离不开 CLI,那我就先从这两个地方下手。先别让问题继续散在群里,后面哪里不够,再继续补哪里。
这套机制是被现场一步步逼出来的,没有预先设计好再推:先把群里的问题接进来,不再靠谁看见谁回;再补跟进、反馈和责任;再把重复问题沉成 SOP、脚本和命令;等材料多起来,再用 CLI 去管格式、上下文和归档质量。到这一步,AI 排优先级、bug checklist 和需求门禁,才接得上。
值班卡住的地方,不是响应慢,而是问题没有被结构化
最早那套模式,表面上看是响应不够快,往下看其实是几层失控叠在一起:
- 值班按人轮,但每个人熟的领域并不一样。轮到谁,谁就得接,不熟也得硬上。
- 同一时间多个一线来追,研发注意力被打碎,现场很容易顾不过来。
- 值班人既要接问题,又被迫改不熟悉的代码,临时修完一个,往往又埋进去新的问题。
- 公司口头上强调“不贰过”,但如果经验只留在某个人脑子里,组织层面还是会反复踩同一个坑。
所以我后来把这件事重新定义了一下:问题出在外部感知没有被结构化。问题一旦还停在群聊里,它就只能制造焦虑,没法稳定追踪,没法统一排序,也没法真的反推出系统当前最痛的技术债。
先别急着做系统,先把问题低摩擦地接进来
我先做的,还是把问题从群聊接进工单状态机里。因为这一步不做,后面的分析、资产沉淀和门禁都没基础。但我当时很清楚,主线是先让这件事跑起来,搞工单系统从来不是目的。工单只是我借来把这件事跑起来的工具,重点始终在于把问题低摩擦地接住。
但企业内这类东西最怕的就是摩擦太大。你如果要求所有人先改习惯、先适应一整套新系统,最后大概率就是流程设计得很完整,实际没人愿意用。对企业内落地来说,低摩擦比完全体更重要,最好是整个逻辑流程尽量无感。 大家几乎不用重新学习,这套东西才有机会被持续使用。
入口先别靠记忆
我先把工单入口直接挂到了个人名片和日常协作位置上,让一线在最顺手的地方就能看到,不用再问“这个问题该找谁”。
入口有了以后,表单字段我也没有一股脑全扔给一线。我的做法是分层:
- 一线只填最必要的信息,比如问题现象、客户、版本、问题关联群。
- 值班和研发再补分类、责任人、是否归档 SOP、关联缺陷这类治理字段。
原因很简单:一线提单成本太高,入口就会废;字段太少,后面又没法追踪和分析。关键在于先把外部问题顺利接进系统,后面才谈得上排序和改进。很多企业内流程挂掉,多半是使用成本太高,跟价值够不够反倒关系不大。
我另外立了一条硬规则:值班负责先接住、先判断、先给临时方案,但长期问题和代码修复必须回到领域 owner。值班不是替所有人背锅,更不是谁轮到谁就永久接手别人的系统。
处理过程必须可追踪
光有表单还不够,关键是提单之后不能再掉回群聊里失踪。所以我用智能表格的自动化流程,把提醒和状态流转接上了。我当时连预算都算过,企业微信智能表格每月那点自动化次数,对我们这种量级刚好够用,便宜得很,反而更说明没必要急着自己搭一套。
- 一线提单后,通知会自动发到对应人和对应群。
- 超时不处理会触发提醒,逼着状态从“未处理”往前走。
- 处理完以后还能回到原问题记录,不会只剩聊天截图。
再往后,问题不只是“有没有通知”,还得能被持续回看。于是我把状态、SOP 归档、TD 号、结果排查进展、响应人这些字段都挂进同一套视图里。早会、周会、回溯、查漏,都直接基于这张表看。
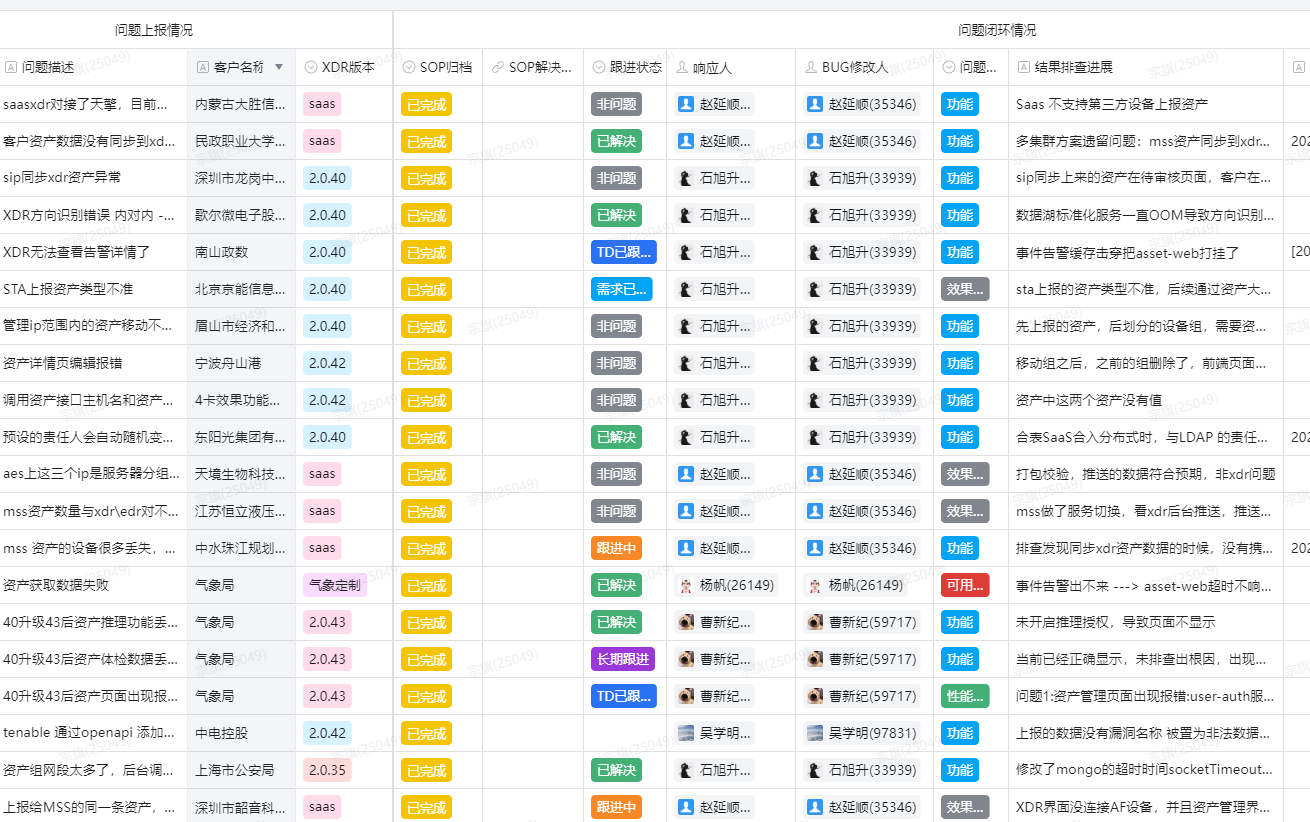
我想要的就是这个:问题终于能被当成数据来看。它已经从散在群里的聊天记录,变成后面做聚类、排优先级、做复盘、做门禁时都能直接拿来用的输入。而且这套东西几乎不要求大家额外学习什么新东西,这一点在企业里比“功能做全”更重要。
结束以后还要有人认账
以前很多处理其实停在“技术同学说已经搞完了”。但对一线来说,问题是不是处理到位了,感受往往不是一回事。所以我又补了一步:处理结束后让一线回评价。
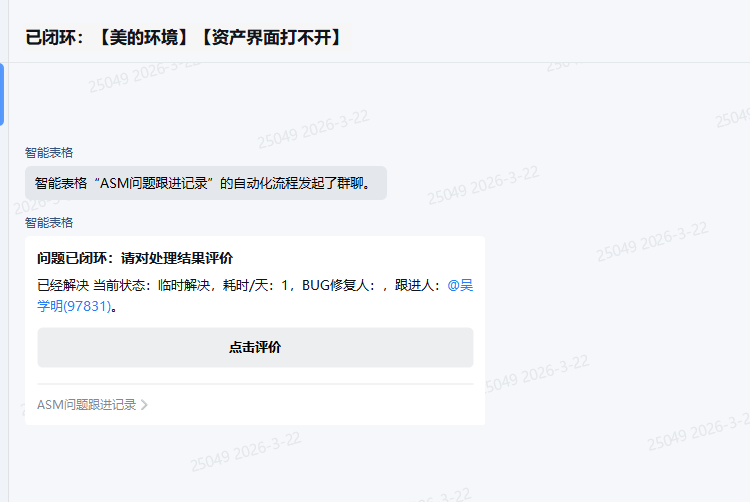
这一步很重要,因为它逼着流程不能只算“工单结束”,还得看结论有没有被一线确实接住。对我来说,这些评价不是形式,它们本身就是外部感知的一部分。谁痛、谁急、谁反复追,后面都应该进优先级分析。
事情接住以后,我才开始补第二层
跑了一阵以后我才发现,光把问题接住还不够。如果团队每天只是不断响应,最后通常是值班越来越熟,组织却还是越来越累。要把这件事再往前推一步,就得同时做两件事:
- 第一条线是继续响应问题,先把客户和一线眼前的事接住。
- 第二条线是把每次处理问题留下来的材料沉成素材库,再把素材库变成组织资产。
第一条线解决的是“现在别炸”。 第二条线解决的是“以后别再这么累”。
这两条线也不是同一天一起长出来的。先有第一条线,因为现场已经在追着跑;第二条线是第一条线跑了一阵以后,被重复问题和重复劳动逼出来的。
第一条线:先把问题响应住
这条线其实最务实,没有那么多漂亮话。客户来问题了,一线来追了,团队就得先有人接、先有人判断、先有人给结论。但我还想多做一层:别让一线总有一种“还是我在推着这个问题往前走”的感觉。最好是问题一旦进系统,后面的提醒和流转就自己开始走,而不是继续靠谁嗓门大谁盯得紧。
对外当时就两句话:
- 当日必接
- 3 天必给结论
我一直强调的是“给结论”,不是“立刻修完”。因为 ToB 现场很多问题本来就不可能秒解,但你不能让一线和客户一直挂在半空里。先把响应和结论稳定住,团队才有资格谈后面怎么系统性地改。
第二条线:把处理问题的材料沉成素材库
但我很快也发现,只靠第一条线不行。大家当然能把问题一个个处理掉,可如果每次处理完,经验还只是留在某个人脑子里,下次遇到类似问题,团队还是得重新组织命令、重新拼排查步骤、重新补上下文。人会越来越累,值班也会越来越像体力活。
一直这样。
所以我后来重点补的,就是第二条线:积累问题素材库。
这个素材库里装的东西比“文档”两个字要具体得多,是几类确实能复用的技术资产:
- SOP 标准处置流程
- 脚本和命令模板
- 高频 SQL 和排查片段
- 一线常见问题的标准口径
- 每次问题处理过程中沉下来的上下文和边界
脚本、命令模板、SOP、checklist,其实都是一类东西:把这次已经验证过的处理能力,转成下次别人也能直接拿来用的东西。
素材开始变多以后,我才把它们收进 Claude CLI
一开始我也不是先想到 CLI。最早只是把能留下来的都尽量留下来,SOP、脚本、命令、SQL、处理边界,先别再散在聊天记录和个人电脑里。可材料一多,新的问题马上就来了:同样叫 SOP,有的写得很完整,有的只留半截;有的上下文齐全,有的只剩一句“按上次处理”;有的能复用,有的看完还是不知道该怎么下手。材料开始积起来以后,素材质量本身又成了一个问题。
这时候我才决定不用重后台,直接往 CLI 上收。原因也很简单:对程序员来说,CLI 本身就是最熟悉的工作界面。我这里用的就是 Claude CLI,也是一种 AI agent 工作方式。你让它在 CLI 里查 SOP、补上下文、归档处理经验,这件事的摩擦远比再切一个后台低得多。
后来我想得更直接一点:我们内部这类问题,规模本来就可控,完全没必要再专门搭一套 RAG 知识库。Git 仓库本身就可以是知识库,agent 去检索里面的 SOP、脚本、命令和历史处理材料,对当前场景已经完全够用。
我看重的也不是性能。内部用的时候,最重要的是知识准不准、上下文是不是对、拿出来的东西能不能直接用。只要检索足够准,响应慢一点根本不是问题;成本也完全可控。跟再去维护一套额外的向量库、切分策略、索引同步链路相比,直接让 agent 在 Git 仓库上工作,反而更贴合我们当时的实际需要。
所以我后面把 SOP 的生产和消费都往 CLI 上收。重点在于约束资产质量,同时降低人去组织 SOP 的难度:
- SOP 要按固定格式写
- 没写清楚就不能直接归档
- AI 先提示补上下文,再允许入库
- 入库以后,值班和研发都能继续按 CLI 的方式检索、追问和复用
这套 CLI 机制,说白了就是素材整合加素材门禁。先把零散经验、脚本、命令、排查路径组织起来,再用格式和上下文要求把质量卡住。
素材和 SOP 跑顺以后,微信机器人才像回事
素材库起来以后,微信机器人这层才开始派上用场。它的作用是把已经沉下来的组织资产,用最省事的方式重新送回现场。
而且这时候 Git 的价值也出来了。知识库、脚本、SOP 这些东西一旦都回到 Git 里,天然就有版本管理、review 和多次修正的能力。脚本不是某个人电脑里传来传去的小文件,SOP 也不是发在群里的半截说明,它们都开始像正经资产一样被维护。对我来说,这比“再搭一个更像知识库的平台”更重要,因为它既保住了知识的精准性,也没有把维护成本再往上抬。
所以我一直不把它理解成“做了个机器人”,而是把它看成素材库的对外使用面:一线和研发不一定要亲自翻仓库,但他们能先通过机器人命中已经沉下来的 SOP、脚本、命令和问题口径。这样大家处理问题时就没那么累了,因为很多事情终于不用再从零组织一遍。
再往后,我才敢让问题反推技术债优先级
只把问题响应住,再把素材沉下来,事情走到这一步才开始有意思。因为我发现,前面这两条线留下来的数据和资产,已经足够反过来回答一个更关键的问题:到底什么才是现在最该解决的技术债?
以前团队内部也会说“这个模块历史债很重”“那个地方代码丑”“这里迟早要重构”。这些判断并不是没道理,但它们太容易变成内部视角。真到了 ToB 现场,很多内部觉得重要的问题,客户未必有感;反过来,那些客户反复提、反复追、反复影响交付的问题,才是系统眼下真正痛的地方。
所以后来我直接把这批结构化的问题数据交给 AI 去分析。它关注的角度更接近外部感知,比如这几类信号:
- 哪些问题被不同人反复提到
- 哪些问题跨客户重复出现
- 哪些问题长期占着大家注意力
- 哪些问题表面现象不同,底层其实是同一类债
- 哪些问题一旦出现,外部感知会特别差
到这时候,问题反推技术债这件事就不再是一句好听的话了。它已经可以直接把团队从凭感觉排优先级,拉到先解决外部已经反复感知到的问题。被大家持续关注的,才是真问题;我们自己以为的问题,很多时候未必是当前最该优先解决的问题。
我原来草稿里写过一个排序公式:影响面 × 频次 × 不确定性 ÷ 修复成本。但它前面还得再补一句:外部感知优先。如果客户、一线和交付现场已经连续在这个点上被打疼,那它哪怕在代码层面看起来没那么“高级”,优先级也该往前放。因为你要先修系统当前真正伤人的地方,而不是先修团队自己最有表达欲的问题。
最后一层,才是把历史问题前移成 checklist 和门禁
如果事情只停在“AI 帮我们排优先级”,那它还不够硬。能把质量治理往前推一大步的,是问题不能只停在这次工单和这次复盘里,它得变成后面需求和代码阶段就能用的资产。
所以我又做了一层主动拉取 bug 平台的 skills——直接把 bug 平台里的问题拉下来,做归类、做抽取、做归档,再把它们沉成 checklist。
这一步改变很大。因为问题一旦被固化成 checklist,它就会进入后续门禁,不会停在“这次知道了”就完了:
- 新需求进来,先跑一遍历史归档 checklist
- 看这次需求会不会重新踩到以前的坑
- 看如果会踩,应该在设计、实现还是验证阶段把它处理掉
- 把“怎么解决”提前,而不是等上线后再靠值班补救
这样“不贰过”才第一次像是个机制,而不是一句口号。关键在于把历史问题变成后续写代码和做需求时必须经过的一道门,不能光靠大家记住。
这时候,这套机制才算闭起来:外部感知进入工单 -> 问题处理过程被挂起来 -> 素材沉进 Git + CLI -> AI 判断优先级 -> bug skills 拉取归档 -> checklist 进入需求门禁。
以前靠个人记忆扛住的问题,到这时候才开始往组织资产上沉。
整个闭环画出来大概是这样:
flowchart TD
A["外部问题进入工单"] --> B["处理过程可追踪"]
B --> C["素材沉进 Git + CLI"]
C --> D["AI 排优先级"]
D --> E["归档为 checklist"]
E --> F["进入需求门禁"]
F -->|"问题前移,减少救火"| A
这套东西最后到底带来了什么
这套机制跑起来以后,我们月均大概有 60 条问题,资产命中率在 70% 左右。也就是说,一个月里会有四十多条问题,不需要每次都从零排查。命中类问题通常半小时左右就能给出处理动作;没命中的问题复杂得多,但机制上要求 3 天内必须给出结论和下一步路径,而不是无限悬着。
对外承诺也一直没变:当日必接,3 天内给结论。
这里承诺的是“给结论”,不是“3 天内一定修完”。这个边界特别重要。ToB 现场里,复杂问题本来就不可能都秒解,但不能一直没人接、没人说清楚、没人负责往下推。
对内实际的收益,也远不只是“有了一张表”:
- 高频问题进入标准救援通道
- 复杂问题进入改进分流通道
- 外部感知开始直接影响技术债优先级
- 历史 bug 开始沉成 checklist,进入需求和代码门禁
- 脚本、命令和 SOP 被当成一类技术资产持续复用
- SOP 从散知识变成了带格式约束、能被 CLI 持续复用的资产
回头看,我做的其实就是一条把外部问题一步步变成组织能力的链路:先接住问题,再挂住过程,再沉下素材,最后把历史问题前移成优先级和门禁。
我想做的事情其实一直没变:把原本只掌握在个人手里的排查能力、脚本能力和 SOP 组织能力,一点点转成团队可以复用的组织能力。质量管理能不能站住,最终看的是后面的人是不是越来越不需要靠某一个人来救火。
如果你也在做类似的工程质量改进,这两篇可以一起看: