性能优化
收录于 工程治理体系
QPS 激增时,先别盯数字,先看流量长什么样
QPS 激增时,真正决定你该怎么救火的,往往不是峰值多少,而是流量到底是一根针还是一堵墙,系统又是在算不过来还是等不过来。
线上接口一出事,很多团队第一眼都会去看 QPS。
这几乎是条件反射。监控图上最扎眼的是它,报警里被反复提到的通常也是它。可真到救火现场,QPS 只是在告诉你“系统现在很忙”,还没告诉你“为什么会这么忙”,更没告诉你“你现在该先动哪儿”。
从那次事故以后,我在意的是两个问题:
- 这股流量,长什么样?
- 我的系统,在怎么喊疼?
这两个问题不是总结出来的排障口号,是一次真实事故硬逼出来的。
QPS 高了,但问题不只是 QPS 高了
那次是晚上发现服务开始往下掉的。值班消息先过来,说有个我们原来以为不怎么会被大量调用的接口,错误率和延迟一起往上跳。我们自己没有发版,时间也不在预期会突然放量的窗口里,第一反应就是“怎么会突然挂成这样”。
那个接口平时存在感不强,我们一直以为它不是会先出事的点。有一次它的 QPS 在很短时间里突然抬上去,接口延迟、错误率、线程阻塞、数据库连接池占满,几乎是一串信号一起往上跳,服务很快就开始往雪崩方向滑。
如果只是站在监控面板前看,很容易得出一句没什么用的话:
QPS 太高了。
这句话的问题不是它错了,是它几乎不能指导动作。有用的信息不是“它高”,是:
- 这波流量是怎么涨上来的。
- 它打在了哪里。
- 它为什么会把系统打成现在这个样子。
这几件事不看清,后面不管是限流、扩容、查 SQL 还是找调用方,动作都很容易打偏。
先看流量是一根针,还是一堵墙
我那次第一眼直接跳过峰值数字,先看流量分布。
结果很快就看出来了,流量更像一根很尖的针。新增流量几乎都扎在同一个原本不怎么起眼的接口上,整站其他部分没怎么动。
这个判断很关键。
如果是大部分接口一起涨,更像是整体入口放量、活动流量、统一推送,或者大范围扫描、攻击,方向通常要往全局入口和整体容量上看。
但如果只有一个接口被猛打,问题大概率是局部的。它更像是某个调用方、某条链路、某个业务动作出了问题,把压力集中送到了一个单点上。
接着我去看这些请求干不干净。
看下来也很快,方向更清楚了:
- 请求格式正常。
- 参数结构符合业务特征。
- 调用身份清晰。
- 没有明显攻击特征。
- 来源高度集中在某个固定调用方。
到这一步,其实已经能先排掉一大块误判。
不是脏流量,不像恶意攻击。它是干净、合法、但已经失控的业务流量。
这类流量往往最麻烦。因为它不会用异常参数提醒你,也不会用脏特征暴露自己。它看起来像正常调用,只是调用模型已经悄悄变了,系统还没来得及适应。
再看系统是算不过来,还是等不过来
确认完流量形态以后,第二步我会立刻去看系统先在哪儿喊疼。
那次最早顶不住的,不是 CPU,也不是机器本身,而是数据库连接池先被打满了。后面看到的线程阻塞、请求排队、延迟上升和错误率飙升,本质上都在顺着这个点往外传。
当时我顺手留了一张线程图。Active Application Threads 在 22 点后很快贴着 Max Thread Pool (500) 那条红线往上顶,中间偶尔掉下来一点,很快又被重新顶满。那张图对我很有帮助,因为它说明线程已经不在做计算了,全卡在等待里越堆越满,执行槽位已经快被占死了。
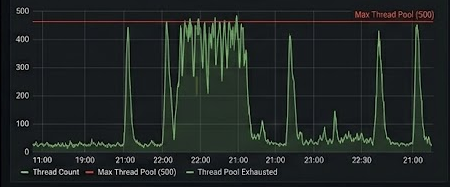
这件事对判断特别重要。
因为它说明问题已经超过了“请求多了”这么简单——这些请求以一种很不友好的方式,直接穿透到了后端关键资源,把数据库这层先压死了。数据库一慢,线程就开始等;线程一等,请求就开始堆;请求一堆,延迟和错误率就会一起上来。
就这么垮下来的。
所以那次系统喊疼的方式很明确:
不是算不过来,
而是等不过来。
我后来处理类似问题时,会先粗暴地区分这两类:
- 如果是 CPU、序列化、正则、加解密这类地方先爆,通常更像算不过来。
- 如果是数据库、Redis、外部依赖、线程池、连接池先顶住,多半是等不过来。
这两个方向后面的动作差很多。一个更可能去看计算热点、对象创建、代码路径;另一个更应该优先看依赖承压、资源池耗尽、同步等待和请求排队。
线上先止血,别急着一上来找真相
故障现场很容易掉进一个误区:大家都急着讨论根因,反而忘了先把系统救活。
那次我们跳过了开会环节,直接上手做了几个动作:
- 先对那个接口做紧急限流。
- 给热点数据补缓存,先把数据库压力卸下来。
- 按调用方维度把流量拆开,确认到底是谁在把请求打进来。
- 立刻联系上游团队,问最近有没有发布、改造或调用模型变化。
这些动作不一定优雅,但在事故现场它们有共同目标:先止血。
系统没稳住之前,真相再完整也没意义。只有先把服务从雪崩边上拉回来,后面的日志、链路、发布记录和调用模型才有机会慢慢看清。
根因不在流量脏,在调用模型被放大了
服务稳住以后,顺着日志和调用链继续查,异常流量几乎都指向同一个调用方。再和对方对上发布信息,事情就清楚了。
他们当时在做一轮多租户改造。
问题不在“多租户”本身,在于改造以后,调用模型已经被放大了。
原来一次相对简单的业务动作,改完以后被拆成了多个租户、多个资源维度下的重复查询。这些查询没有在上游先做聚合,也没有异步化、批量化和缓存,而是直接同步打到了我们那个原本没按高流量场景去准备的接口上。
从他们那边看,可能只是功能支持范围扩大了。
从我们这边看,事情完全不是一个量级:
- 调用次数成倍放大。
- 调用集中扎在同一个接口上。
- 请求继续同步穿透到数据库。
- 关键资源很快被耗尽。
- 最后整个服务被直接打挂。
这次事故既不是攻击,也不是某段代码突然写坏了。它更像一次典型的调用放大事故。
复盘不能只说“问题在他们”
如果只看直接诱因,这件事的责任当然主要在上游。
他们做改造时,没有充分评估对下游的调用放大,也没有把节流、聚合、缓存和容量验证一起补上,更没有在改调用模型之前先同步关键下游。
但如果复盘只停在这里,这件事其实还是没被消化掉。
因为我们自己也暴露了很真实的脆弱性。
我们确实没有制造这波异常流量,但系统还停在“别人用错了,就会立刻被打死”的状态——这是我们自己要补的课。比如:
- 缺少更细粒度的限流、隔离和降级。
- 对重要调用方的行为变化感知不够快。
- 没把调用方维度的容量约束做成明确契约。
- 接口虽然能用,但没有明显引导上游以更安全的方式使用。
这次事故里,上游把问题带进来了,但我们把脆弱性留在了系统里。
现在再看 QPS 激增,我会先做哪几层判断
经历过这类事故以后,我不喜欢那种“QPS 高了,开始背排障 SOP”的处理方式。
因为 QPS 激增背后经常连着调用模型变化、系统边界失真、容量假设落空,甚至是跨团队协作没有跟上。
所以现在我看到 QPS 抬头,习惯先过这几层判断:
- 先看流量形态。它是一根针,还是一堵墙?是集中打一个接口,还是整站一起抬。
- 再看流量质地。它是攻击、脚本、脏流量,还是合法但失控的业务调用。
- 再看系统先在哪儿疼。是 CPU 在烧,还是连接池、线程池、数据库、外部依赖先顶住。
- 先做止血动作。别把救火拖成纯分析题。
- 服务稳住以后,再回头查调用模型、发布变更和边界保护为什么同时失效。
这套顺序看着不复杂,但它能把“一个大数字”拆成更能指导动作的几个问题。
我后来越来越觉得,故障现场从来不缺监控图,缺的是有人愿意把图背后的关系先看明白。QPS 当然重要,但它说到底只是最外层那个结果。决定你怎么救火的,是流量长什么样,系统又是在怎么喊疼。